我刚刚发现 Everything 1.5 可以搜索十六进制值内容。棒极了!非常感谢!正是我现在需要的!
但现在我有几个问题:
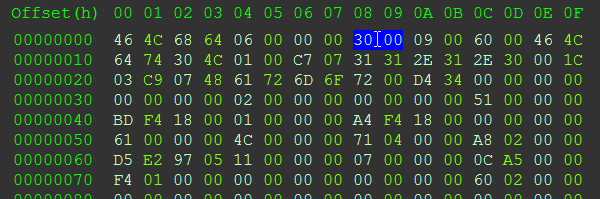
1) 我怎样才能在第 9 个和第 10 个字节上搜索特定的十六进制值?
通过写这个,我可以列出所有包含十六进制值 30 00 的文件,这是正确的吗?
代码: 全选hex:content:3000
但是有没有办法只在第一个“行”的第 9 个和第 10 个字节上找到所有具有这些十六进制值的文件?
真的希望有一种方法,因为这实际上可以为我节省大量的工作时间。
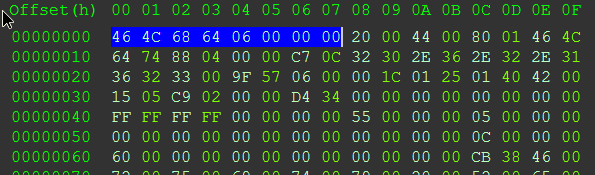
2)我也注意到,如果我这样写整行
代码: 全选hex:content:”464C686406000000″
或者像这样:
代码: 全选hex:content:”464C6864060000002000″
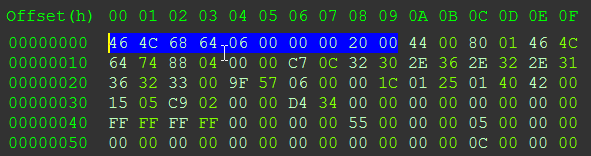
我没有得到任何结果。
有人可以解释我为什么吗?
解决办法:在 Everything 1.5 中,当你使用 content: 函数时,它只会搜索索引内容。并且该内容已由 iFilter 进行预处理。这意味着,例如,PDF 文件将被理解 PDF 文件并能够从中提取纯文本的程序读取。在这种情况下,Everything都不会看到十六进制代码。
您可以尝试以下操作,但不能保证,因为还有更多需要考虑的事项(而且我在这方面的知识有限):
代码: 全选”C:\this folder” ext:pdf regex:hex:notindexed:ansicontent:^.{8}3000
(用适合您情况的东西替换“C:\this folder”和 ext:pdf;为了测试,从有限数量的文件/文件夹开始。
这将搜索没有内容索引的文件,所以它会慢点(呃)。